Table e Table Extensions
Cosa sono le Tabelle
Le tabelle sono gli oggetti principali utilizzati per archiviare i dati in Dynamics 365 Business Central. Indipendentemente dal modo in cui i dati vengono registrati nel prodotto, da un servizio Web a un tocco del dito sull'app del telefono, i risultati di tale transazione verranno registrati in una tabella.
Una volta completata l'analisi funzionale e la definizione dei processi, qualsiasi nuovo lavoro di progettazione deve partire dalla struttura dei dati. Per Business Central, ciò significa le tabelle e i loro contenuti.
Una tabella è composta da due parti:
- i dati della tabella
- la definizione della tabella.
La definizione della tabella descrive la struttura dei dati e il suo comportamento, e può essere modificata solo da uno sviluppatore, mentre i dati sono variabili e dipendono dalle attività degli utenti.
Una tabella su Business Central è composta da:
- Proprietà: dove è possibile configurare il comportamento della tabella.
- Trigger: dove viene scritto codice che verrà eseguito in determinati momenti.
- Campi: definiscono il tipo di dati che la tabella può contenere. I campi possono avere proprietà e trigger.
- Chiavi: la chiave è necessaria per creare record univoci ma anche per definire come ordinare i dati.
- Fino a 500 campi
- Grandezza del record massima di 8000 bytes
- Fino a 40 chiavi differenti
Relazioni tra tabelle e proprietà Table Relation
E' comune distingure i seguenti tipi di relazioni tra le tabelle nella progettazione di database relazionali:
- Relazione uno-a-molti
- Relazione molti-a-molti
- Relazione uno-a-uno
Se il database contiene tabelle con dati correlati, è possibile definire una relazione tra di esse. E' possibile correlare le tabelle specificando uno o più campi che contengono lo stesso valore nei record correlati. E' possibile utilizzare le relazioni per:
- Convalidare le voci di dati
- Eseguire funzioni di ricerca in altre tabelle
- Propagare automaticamente le modifiche da una tabella ad altre tabelle.
Le relazioni tra tabelle vengono definite nell'ambiente di sviluppo del lnguaggio AL utilizzando la proprietà TableRelation. Questa proprietà consente di definire relazioni di tabella sia semplici che avanzate.
E' possibile definire una relazione solo con un campo membro del gruppo di chiavi primarie.
Esempio - Table Relation
table 50120 TableWithRelation
{
fields
{
field(1; Id; Integer) { }
field(2; Type; enum TypeEnum) { }
field(3; Relation; Code[20])
{
TableRelation =
if (Type = const (Customer)) Customer
else if (Type = const (Item)) Item;
}
}
}
Table Properties
-
ID: è un numero che deve essere compreso nell'intervallo di numeri che ricevi da Microsoft quando diventi un partner Dynamics 365 Business Central. Garantisce che nessun oggetto avrà lo stesso ID in un database.
-
Name: è il nome della tabella, ogni nome di tabella è al singolare. La tabella deve avere un nome inglese e si deve utilizzare un prefisso/suffisso nel nome del tuo oggetto in modo che sia univoco.
-
Caption: la capiton è l'intestazione mostrata all'utente, è definita per la lingua corrente (la lingua di default è US). Questa proprietà è visibile solo quando esegui la tabella direttamente senza una pagina.
-
Permissions: permette di definire i livelli di accesso alla tabella (r for read, i for insert, m for modify and d for delete).
-
LookupPageId: ci permette di definire quale pagina è la predefinita per quando si esegue il lookup della tabella.
-
PasteIsValid: determina se gli utenti possono incollare i dati nella tabella.
-
DataCaptionFields: consente di costruire la didascalia (caption) utilizzando i contenuti di campi specifici. Ad esempio, considerando una tabella di clienti, se si imposta "DataCaptionFields" con i campi "No." e "Name", la barra del titolo visualizzerà la combinazione di questi due campi come didascalia.
-
DataPerCompany: le company sono la struttura logica più grande nel database di Business Central. Puoi scegliere di amministrare più di una società in un database. Se scegli più di una società, i tuoi dati vengono comunque mantenuti univoci per ciascuna società. Questo consente di definire se i dati in una tabella sono segregati per società (predefinito) o se sono comuni (condivisi) tra tutte le società nel database.
-
DataClassification: la proprietà DataClassification imposta la classificazione dei dati in una tabella. Questa proprietà può essere utilizzata per aderire ai requisiti di sicurezza, conformità e privacy e al processo di raccolta, archiviazione e utilizzo delle informazioni personali.
-
DrillDownPageId: questa proprietà consente di definire quale pagina è l'impostazione predefinita per l'esplosione dei dati di dettaglio di un campo calcolato.
Table Triggers
Il codice contenuto in un trigger viene eseguito prima dell'evento rappresentato nel trigger stesso.
Questi trigger vengono automaticamente invocati quando c'è un'elaborazione del record da parte dell'utente.
-
OnInsert(): è eseguito quando un nuovo record sta per essere inserito nella tabella tramite l'UI.
-
On Modify(): è eseguito quando il contenuto di qualsiasi campo diverso da un campo chiave primaria è stato modificato. La modifica viene determinata confrontando xRec(l'immagine del record prima della modifica) con Rec (la copia corrente del record). Queste variabili (Rec e xRec) sono variabili definite dal sistema.
-
OnDelete(): eseguito quando un record sta per essere eliminato dalla tabella. BC non fa nulla per mantenere un'integrità referenziale nell'eliminazione.
-
OnRename(): viene eseguito quando una parte della chiave primaria sta per essere modificata. Ciò mantiene un livello di integrità referenziale. A differenza di alcuni sistemi, BC consente di modificare la chiave primaria di qualsiasi record master. Ciò mantiene automaticamente tutti i riferimenti chiave esterna interessati da altri record.
Table Keys
Le chiavi identificano le righe combinando una o più colonne di una tabella. SQL utilizza inoltre gli indici per velocizzare il recupero dei dati dalle righe di una tabella.
Chiavi in AL
In AL, una definizione di chiave è una sequenza di uno o più ID campo di una tabella. E' possibile definire le chiavi negli ogetti estensione tabella, a seconda del tipo di chiave. Esistono due tipi di chiavi:
- CHIAVE PRIMARIA, è in grado di identificare in modo univoco ciascun record all'interno di una tabella. Ogni tabella è dotata di una sola chiave primaria. Le chiavi primarie vengono definite esclusivamente negli oggetti tabella.
In linguaggio SQL, gli oggetti di estensione della tabella ereditano la chiave primaria dall'oggetto tabella da cui derivano (l'oggetto tabella di base). Di consegnuenza, qualsiasi chiave definita in un oggetto di estensione della tabella viene considerata come chiave secondaria.
- CHIAVE SECONDARIA, serve a creare indici in SQL e può essere definita sia negli oggetti tabella che negli oggetti estensione tabella. E' possibile definire più chiavi secondarie per un singolo oggetto estensione tabella.
Nel contesto degli oggetti estensione tabella, un chiave può comprendere campi provenienti sia dall'oggetto tabella di base che dall'oggetto estensione tabella. Tuttavia, occorre tener presente sempre alcune limitazioni.
Chiavi Primarie
La chiave primaria in una tabella svolge un ruolo fondamentale nel tracciare e identificare in modo univoco ogni record. Questa chiave, composta da un massimo di 16 campi in un record, è definita come la prima chiave in un oggetto tabella in AL. La sua presenza determina l'ordine logico degli archivi dei record, indipendentemente dalla disposizione fisica dei campi nell'oggetto tabella.
La disposizione logica dei record segue un ordine crescente basato sulla chiave primaria. Prima di inserire un nuovo record, SQL Server verifica l'unicità delle informazioni nei campi della chiave primaria, posizionando il record in modo appropriato nella sequenza logica. Questo ordinamento dinamico mantiene la struttura corretta del database, facilitando la manipolazione e il recupero dei dati.
La chiave primaria è sempre attiva e SQL Server mantiene la tabella ordinata in base all'ordine della chiave primaria, respingendo i record con valori duplicati nei campi chiave. La necessità di unicità nei valori della chiave primaria non riguarda il singolo valore in cascun campo, bensì la combinazione di valori in tutti i campi che costituiscono la chiave primaria.
Nell'ambiente di sviluppo, è tecnicamente possibile creare una chiave primaria basata su un massimo di 20 campi. Tuttavia, a causa delle limitazioni di SQL Server, vengono utilizzati solo i primi 16.
Chiavi Secondarie
In un oggetto tabella, tutte le chiavi definite dopo la chiave primaria sono denominate chiavi secondarie, mentre tutte le chiavi definite in un oggetto estensione tabella sono considerate chiavi secondarie.
Una chiave secondaria in SQL Server, è implementata attraverso una struttura chiamata indice, simile a un indice di un libro di testo. L'indice elenca in ordine alfabetico i termini importanti alla fine del libro, con i numeri di pagina accanto a ciascun termine. Questo permette una rapida ricerca per individuare i numeri di pagina associati a un termine specifico.
Quando si definisce una chiave secondaria abilitata, SQL Server gestisce automaticamente un indice che riflette l'ordinamento definito dalla chiave. E' possibile attivare contemporaneamente più chiavi secondarie. Una chiave secondaria può essere disabilitata per risparmiare spazio nel database o evitare l'utilizzo di risorse durane gli aggiornamenti dell'indice.
E' importante notare che i campi che compongono le chiavi secondarie non sono sempre univoci, e SQL Server non rifiuta i record con dati duplicati nei campi chiave secondaria. In caso di duplicati, SQL Server utilizza la chiave primaria della tabella per risolvere eventuali conflitti.
Chiavi Secondarie Univoche
Una chiave in SQL Server, definita con la proprietà Unique, offre la possibilità di creare un vincolo univoco nella tabella. La caratteristica unica di questa chiave assicura che i record all'interno della tabella non abbiano valori identici nei campi specificati. La validazione della tabella verifica l'unicità dei valori della chiava durante la convalida, e se si riscontrano record con valori duplicati, la convalida finsice.
E' possibile creare chiavi secondarie univoche costituite da più campi, similmente alle chaivi primarie. In questo contesto è fondamentale che la combinazione dei valori nella chiave secondaria sia univoca. Ad esempio, nella tabella Customer, potrebbe essere necessario garantire che non esistano clienti con la stessa combinazione di valori per i campi Nome, Indirizzo, Città, e a tal fine è possibile creare una chiave univoca per questi campi.
A differenza delle chiavi primarie, è permesso definire più chiavi secondarie univoche all'interno di una stessa tabella.
Chiavi di sistema
C'è sempre una chiave secondaria univoca nel campo SystemId.
Il campo SystemID è un campo del tipo di dati GUID che specifica un identificatore univoco e non modificabile (di sola lettura) per i record nella tabella. Il campo SystemID ha le caratteristiche e il comportamento seguenti:
- Tutti i record devono avere un valore nel campo SystemId.
- E' possibile assegnare un valore personalizzato quando un recd viene inserito nel database. In caso contrario, la piattaforma genererà e assegnarà automaticamente un valore.
- Una volta impostato, SystemId non può essere modificato.
- C'è sempre una chiave secondaria univoca nel campo SystemId per garantire che i record non abbiano valori di campo identici.
- Al campo SystemId viene assegnato il numero di campo 2000000000.
Il campo SystemId è esposto nel codice della piattaforma, ed è consentito di scrivere codice AL su di esso.
Chiavi secondarie con campi inclusi
Con le chiavi secondarie non cluster, è possibile usare la proprietà IncludedFields per aggiungere campi che non fanno parte della chiave stessa. In SQL Server, questi campi non chiave corrispondono alle cosiddette colonne incluse. Una chiave secondaria con campi inclusi può migliorare le prestazioni delle query SQL, soprattutto quando l'indice SQL contiene tutte le colonne della query, sia come colonne chiave che come colonne incluse.
Chiavi Columnstore Non-Cluster
Gli indici Columnstore Non-Cluster sono supportati nelle tabelle.
Con la proprietà ColumnStoreIndex è possibile creare un indice columnstore non-cluster nella tabella in SQL Server. L'uso di una chiave columnstore non-cluster può migliorare le prestazioni delle query durante l'esecuzione di analisi su tabelle di gradi dimensioni.
E' possibile utilizzare un indice columnstore non-cluster per eseguire in modo efficiente l'analisi operativa in tempo reale sul database di Business Central senza la necessità di definire gli indici SIFT in anticipo.
Chiavi Cluster e Non-Cluster
Una definizione di chiave include la proprietà Clustered utilizzata per creare un indice cluster. Un indice cluster determina l'ordine fisico in cui i record vengono archiviati in tabella. In base al valore della chiave, i record vengono ordinati in ordine crescente. L'utilizzo di una chiave cluster può velocizzare il recupero dei record.
Può essere presente solo un indice cluster per tabella. Per impostazione predefinita, il database primario è configurato come chiave cluster.
La proprietà non è supportata negli oggetti estensione tabella.
Ordinamenti e chiavi secondarie
Nell'esempio seguente viene illustrato come la chiave primaria influisca sull'ordinamento quando è attiva una chiave secondaria. La tabella Cliente include quattro voci(record) e i record nella tabella Cliente hanno due campi: Numero cliente e Nome Cliente. Nella tabella seguente è incluso l'elenco delle chiavi per la tabella Customer.
| Chiave | Tipo di chiave | Definizione |
|---|---|---|
| 1 | Primario | Numero cliente |
| 2 | Secondario | Nome del cliente |
Quando si esegue l'ordinamento in base alla chiave primaria, la tabella Customer è simile alla tabella seguente.
| Numero cliente | Nome del cliente |
|---|---|
| 001 | Cliente C |
| 002 | Cliente A |
| 003 | Cliente B |
| 004 | Cliente C |
Se si seleziona la chiave secondaria per l'ordinamento, l'ordine si basa sul contenuto del campo Nome cliente. Poiché il contenuto di questi campi non è univoco, i record devono essere subordinati in base alla chiave primaria.
| Nome del cliente | Numero cliente |
|---|---|
| Cliente A | 002 |
| Cliente B | 10R |
| Cliente C | 001 |
| Cliente C | 004 |
I due record che hanno lo stesso valore 'Nome cliente' vengono ordinati in base al numero cliente.
Definizione di nuove chiavi
Per definire le chiavi, aggiungere la parola chiave dopo la definizione, quindi aggiungere una parola chiave per ogni chiave: keys fields keys.
keys
{
key(Name1; Fields)
{
}
key(Name2; Fields)
{
}
}
Sostituisci con il testo descrittivo che si desidera utilizzare per identificare la chiave. Sostituisci il nome di un campo che desideri utilizzare come chiave. Se si desidera includere più campi in una singola chiave, separare ogni campo con una virgola.
A una tabella possono essere associate fino a 40 chiavi.
Modifiche chiave
Quando si sviluppa una nuova versione di un'estensione, tenere presenti le restrizioni seguenti per evitare errori di sincronizzazione dello schema che impediscono la pubblicazione della nuova versione:
- Non eliminare le chiavi primarie;
- Non aggiungere o rimuovere campi chiave primaria, né modificarne l'ordine;
- Non modificare le proprietà delle chiavi primarie esistenti;
- Non aggiungere altre chiavi univoche;
- Non aggiungere altre chiavi cluster;
- Non aggiungere chiavi che sono campi della tabella di base.
Data Type
| Tipi di dato | Descrizione |
|---|---|
| Text | Stringa alfanumerica, massimo 250 caratteri, tipo di dati SQL corrispondente: NVARCHAR |
| Code | Stringa alfanumerica maiuscola, massimo 250 caratteri, tipo di dati SQL corrispondente: NVARCHAR, spesso usato come chiave primaria. |
| Decimal | Numero decimale, da -999,999,999,999,999.99 a +999,999,999,999,999.99, tipo di dati SQL corrispondente: DECIMALE |
| Integer | Numero intero, da -2,147,483,647 a 2,147,483,647, tipo di dati SQL corrispondente: INT |
| BigInteger | Intero a 64 bit, numeri interi grandi, tipo di dati SQL corrispondente: BIGINT |
| Binary | Dato binario, tipo di dati SQL corrispondente: VARBINARY |
| Option | Stringa di opzione, elenco di stringhe separate da virgole: valori validi del campo, non può essere esteso da altre estensioni e tipo di dati SQL corrispondente: INT |
| Enum | Collegato a un oggetto enum, può essere esteso con altre estensioni, tipo di dati SQL corrispondente: INT |
| Boolean | Vero o Falso, formattato: Sì o No, tipo di dati SQL corrispondente: TINYINT |
| Date | Valore Data, da gennaio 1, 1753 a dicembre 31, 9999, data non definita (valore di default): 0D, tipo di dati SQL corrispondente: DATETIME |
| Time | Valore Ora, da 00:00:00 a 23:59:59:999, data non deinita (valore di default): 0T, tipo di dati SQL corrispondente: DATETIME |
| DateFormula | Contiene una formula di data, Ex.30D, CM + 1M, D15 (il 15 di ogni mese) |
| DateTime | Una combinazione di data e ora |
| Duration | Differenza (ms) tra due valori DateTime |
| BLOB | Binary Large Object, contiene bitmaps e appunti fino a 2GB |
| Media | Contiene immagini, performance ottimizzate per la gestione delle immagini |
| MediaSet | Una collezioni di immagini, gestione della collezione di immagini |
| RecordID | Rappresenta un riferimento univoco ad un record: contiene il numero della tabella ed i valori dei campi di chiave primaria |
| GUID | Contiene un identificatore univoco binario di 16 byte ovvero 12345678 1234 1234 1234 1234567890AB |
FlowFields
I campi FlowFields rappresentano il risultato dei calcoli definiti nella proprietà CalcFormula. Ad esempio, il campo "Saldo conto" nella tabella "Conto" della contabilità generale mostra il saldo del conto, calcolato come la somma degli "Importi netti" di tutti i movimenti di "Registrazione COGE" associati al conto.
L'utilizzo dei FlowFields migliora le prestazoni, specialmente in operazioni come il calcolo del saldo dei clienti. Nei sistemi di database tradizionale, questa operazione richiederebbe diversi accessi e calcoli prima che il risultato fosse disponibile. Con i Flow Fields, il risultato è immediatamente accessibile. Le prestazioni possono essere ulteriormente ottimizzate abilitando o disabilitando la tecnologia SIFT (SumIndexFieldTechnology).
Da notare che i FlowField non sono campi fisici archiviati nel database, ma rappresentano una descrizone di un calcolo e della posizione in cui visualizzare il risultato. Poichè le informazioni nei Flow Fields esistono solo in fase di esecuzione, i valori vengono automaticamente inizializzati a 0. Per aggiornare un oggetto FlowField è possibile utilizzare il metodo CalcFields(Record). Se un oggetto FlowFields è l'espressione di origine diretta di un controllo in una pagina, il calcolo avveine automaticamente quando la pagina viene visualizzata.
I campi calcolati, inoltre, possono essere implementati usando una proprietà di campo speciale, la proprietà FieldClass. La proprietà FieldClass può essere uno di tre valori:
-
Normal: valore predefinito. Un campo Normale contiene i dati archiviati nel database. La maggior parte dei campi nel database di Business Central sono campi normali.
-
FlowField: i dati non vengono archiviati in una tabella, ma vengono calcolati. Devi anche fornire una formula nella proprietà CalcFormula, che viene utilizzata come formula di calcolo.
-
FlowFilter: progettato per essere utilizzato nella formula di calcolo di un FlowField. Contiene un valore temporaneo, che viene utilizzato per filtrare nella formula di calcolo. Invece di uno sviluppatore che predefinisce un filtro fisso, un FlowFilter consente all'utente finale di fornire un valore che viene poi utilizzato nel calcolo.
FlowFileds - Tipologie
| Tipo di FlowField | Tipo di campo | Descrizione |
|---|---|---|
| SUM | Decimale, Intero, BigInteger o Durata | Somma di un set specificato in una colonna di una tabella. |
| LOOKUP | Qualunque | Cercare un valore in una colonna di un'altra tabella. |
| COUNT | Numero intero | Numero di record in un set specificato in una tabella. |
| EXISTS | Booleano | Indica se esistono record in un set specificato in una tabella. |
| AVERAGE | Decimale, Intero, BigInteger o Durata | Valore medio di un set specificato in una colonna di una tabella. |
| MIN | Qualunque | Valore minimo in una colonna in un set specificato in una tabella. |
| MAX | Qualunque | Valore massimo in una colonna in un set specificato in una tabella. |
FlowField - Esempio
Si consideri la tabella Customer nella figura seguente. Questa tabella contiene due FlowField. Il campo denominato Any Entries è un FlowField del tipo Exist, mentre il campo Balance è un FlowField del tipo Sum.
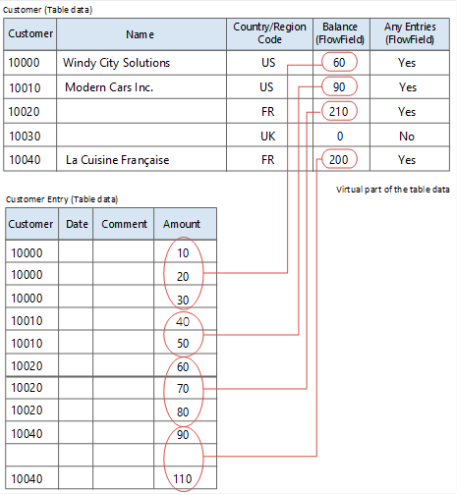
La figura mostra che il valore nel campo Flusso saldo per il cliente numero 10000 (Windy City Solutions) viene recuperato dalla colonna Importo della tabella Movimento cliente. Il valore è la somma dei campi dell'importo per i movimenti che hanno il numero cliente 10000.
Sum = 10 + 20 + 30 = 60.
I valori visualizzati nella colonna Saldo della tabella Cliente per i clienti 10010, 10020 e 10040 vengono visualizzati nello stesso modo. Per il numero cliente 10030 il valore è 0 (zero), in quanto nella tabella Inserimento cliente non sono presenti voci con un numero cliente. Ciò equivale a 10030.
In questo esempio, il campo Flusso saldo nella tabella Cliente riflette la somma di un sottoinsieme specifico dei campi Importo nella tabella Movimento cliente. Il modo in cui deve essere effettuato il calcolo di un FlowField è definito in una formula di calcolo. La formula di calcolo per il campo Saldo è:
Sum("Customer Entries".Amount where(CustNo=field(CustNo)))
Di conseguenza, il campo Tutte le voci, che indica se esistono voci, ha la seguente definizione:
Exist("Customer Entries" where(CustNo=field(CustNo)))
Tipi di tabelle
Le tabelle si dividono in quattro categorie:
-
Tabelle del database: la maggior parte delle tabelle nel database sono tabelle del database. Lo sviluppatore ha i diritti di lettura e scrittura su queste tabelle (esempio: la tabella dei clienti, la tabella dei fornitori e la tabella degli articoli). Si dividono in:
- Master Data: tabelle definite per prime perché tutto il resto si basa su queste(clienti, fornitori, articoli...)
- Journal: contiene delle attività non registrate, altri sistemi si riferiscono a loro come transazioni
- Template: informazioni di controllo alle Journal
- Entry tables: dettagli delle attività di registrazione, le movimentazioni
- Subsidary: liste di codici o descrizioni
- Register: fornisce una panoramica delle sequenze di registrazioni, contiene gli ID transazioni di ogni batch di Ledger Entries registrata
- Posted document: versione storica dei documenti originali, formato testata/righe
- Singleton: sono i setup
-
Tabelle di sistema: le tabelle di sistema sono univoche perché queste tabelle e i relativi dati sono necessari per il funzionamento del sistema. Le tabelle di sistema vengono salvate nel database e avranno numeri di oggetti superiori a due milioni (esempio: la tabella Società, la tabella Profili e la tabella delle Autorizzazioni). Sono delle content modifiable tables: non possiamo modificare la definizione del campo base, ma possiamo cambiarne i contenuti e aggiungere campi.
-
Tabelle virtuali: è possibile trovare la definizione di una tabella virtuale nel database, ma i dati vengono creati in fase di esecuzione, quindi non vengono archiviati nel database. Lo sviluppatore non ha i diritti per scrivere su tabelle virtuali. (esempio: la tabella delle sessioni attive o dei campi).
-
Tabelle temporanee: utilizzata per tenere informazioni temporanee, essa non esiste fuori dall'istanza di ogetto dove è stata definita, esiste solo in memoria. Ha la stessa struttura della tabella permanente da cui è modellata.
Table Extension Object
L'oggetto estensione tabella in Dynamics 365 Business Central offre la possibilità di ampliare e modificare una tabella esistente fornita dal servizio.
Questo consente l'aggiunta di campi supplementari o la modifica di proprietà, rendendo la tabella originale parte di una singola entità più estesa. Ad esempio, immaginiamo la creazione di un'estensione del tavolo per un negozio di sport invernali al dettaglio, in cui si desidera aggiungere un campo cliente supplementare.
Gli oggetti estensione possono avere un nome con una lunghezza massima di 30 caratteri.
L'aggiunta di questa estensione non solo consente l'inserimento di nuovi dati nella tabella dei clienti, ma anche l'integrazione di valori per campi specifici, come ad esempio "ShoeSize". L'estensione della tabella diventa quindi il luogo in cui si scrive il codice trigger per gestire i campi aggiuntivi.
Nel contesto dello sviluppo di una soluzione, è consuetudine seguire un layout di codice specifico per un'estensione di tabella. Tale approccio, illustrato nell'esempio seguete facilita lo sviluppo coerente e la gestione efficace delle estensioni della tabella.
E' possibile estendere solo le tabelle con la proprietà Extensible impostata su true.
Le tabelle di sistema e virtuali non possono essere estese. Le tabelle di sistema vengono create nell'intervallo 2.000.000.000 e superiore.
Le chiavi possono essere definite anche per i nuovi campi aggiunti nell'estensione della tabella, consentendo un maggiore controllo e flessibilità nella definizione delle relazioni. E' possibile estendere le chiavi fornite nella definizione di base o aggiungerne di nuove.
Table extension syntax
tableextension Id MyExtension extends MyTargetTable
{
fields
{
// Add changes to table fields here
}
var
myInt: Integer;
}
Esempio - Table Extension
tableextension 50115 RetailWinterSportsStore extends Customer
{
fields
{
field(50116;ShoeSize;Integer)
{
trigger OnValidate();
begin
if (rec.ShoeSize < 0) then
begin
message('Shoe size not valid: %1', rec.ShoeSize);
end;
end;
}
}
procedure HasShoeSize() : Boolean;
begin
exit(ShoeSize <> 0);
end;
trigger OnBeforeInsert();
begin
if not HasShoeSize then
ShoeSize := Random(42);
end;
}